System Design: Rate Limiter

Rate limiter is used to control the rate of traffic sent by a client or a service. In HTTP world: Rate limiter limits the number of client requests allowed to be send in a given period of time. Once the cap is reached, rate limiter blocks request
Rate limiter is very useful for security and performance improvement when you have very large scale system.
In a nut shell, A rate limiter restricts the number of operations a certain object (user, device, IP, etc.) can do in a given time range.All major tech giants enforce some form of rate limiting
Examples:
- A user can write no more than 5 tweets per second.
- You can login maximum 10times per day from the same IP address.
- You can apply coupon no more than 5 times per month from the same user id.
Why Rate Limiting
- Prevent resource starvation due to a Denial of Service (DoS) attack.
- Ensure that servers are not overburdened. Using rate restriction per user, for example, ensures fair and reasonable use without harming other users. It will also reduce cost of infra also.
- Prevent servers from being overloaded. To reduce server load, a rate limiter is used to filter out excess requests caused by bots or users’ misbehavior
Some Assumptions
- API rate limiter should be on server side.
- It should support all different kind of throttle rules.
- System should have distributed environment.
- It should handle a large number of request.
- This service should not slow down api response time.
- High Fault tolerance and low latency
Lets Sign MoU
Lets put a rate limiter as middle-ware between API Servers and Client request. This middle-ware throttles the requests.
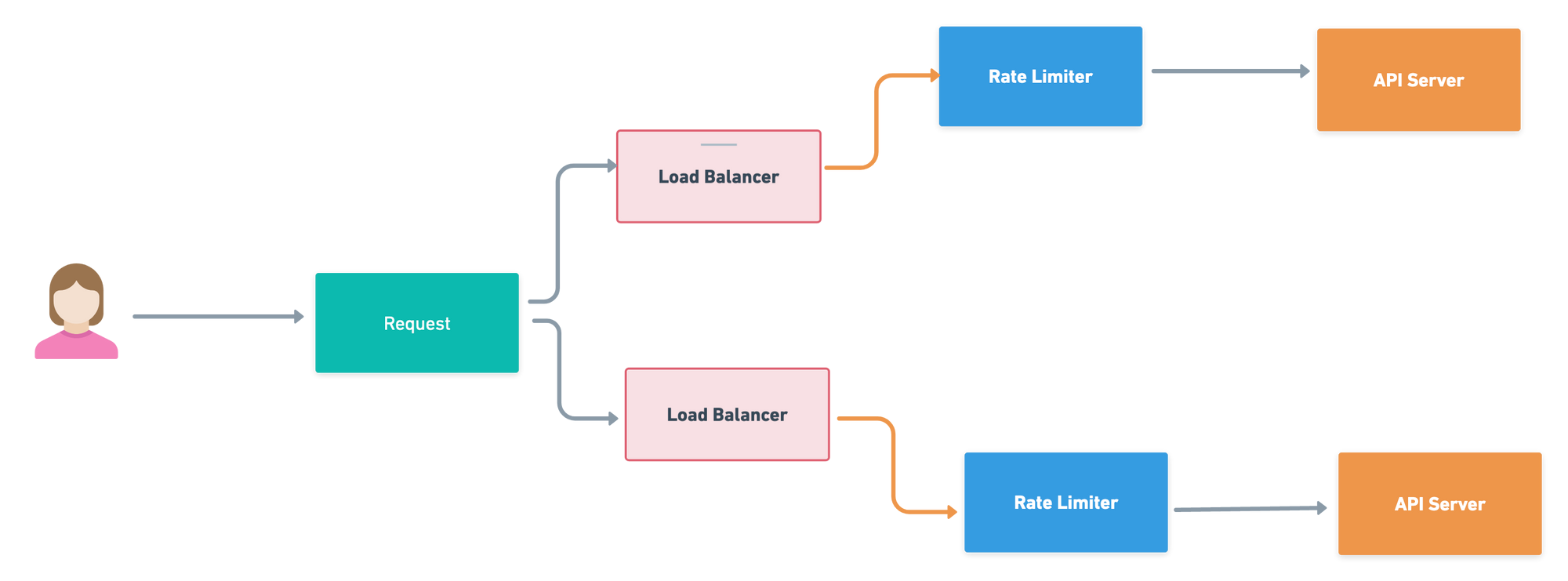
Rate Limiting Algorithm
There are numbers of algorithm through which you can create RL service. Each algorithm has its pros and cons. Let’s discuss about some algorithm :
Token Bucket
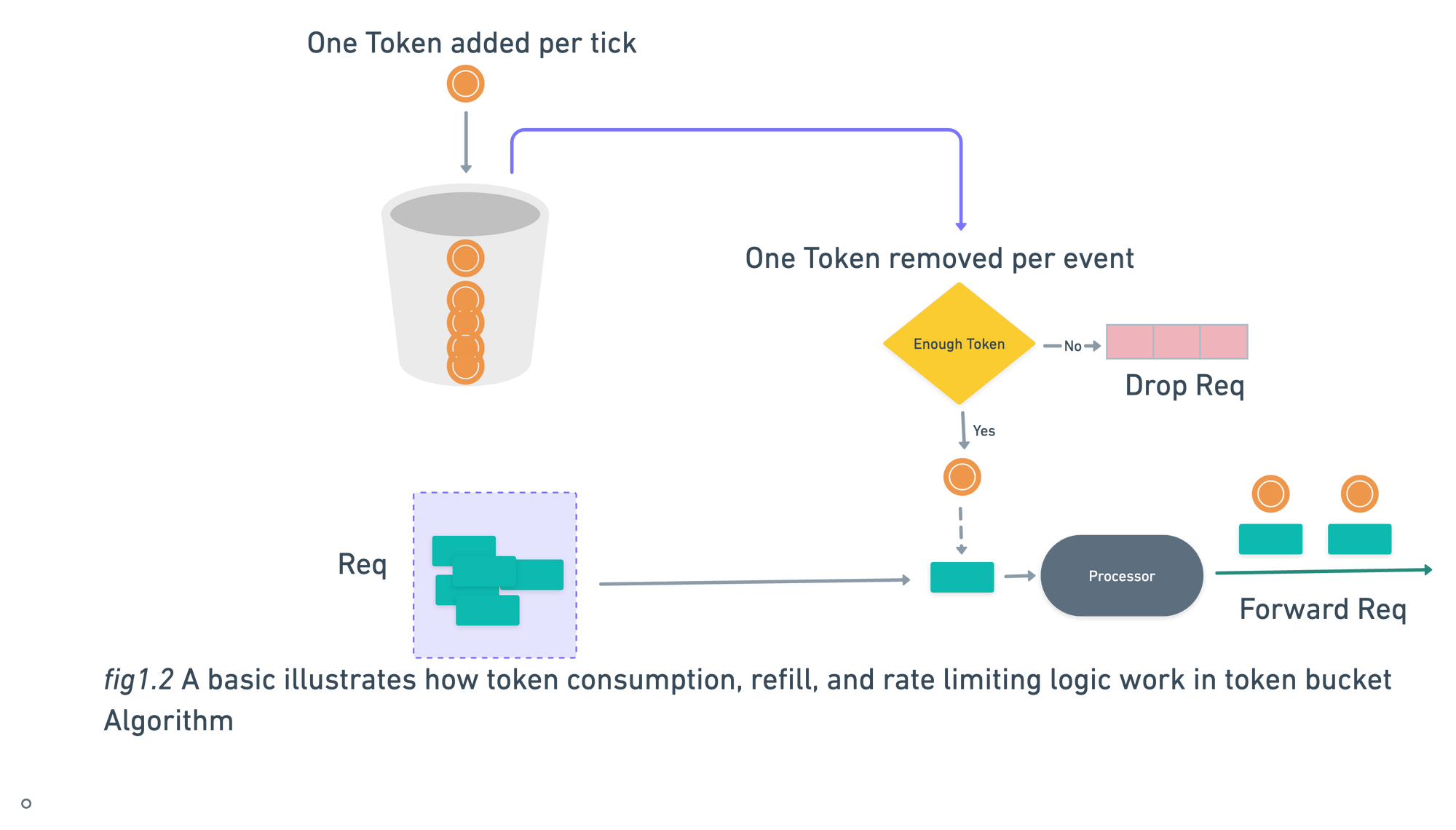
Token bucket algorithm has two variable:
- Bucket size: the maximum number of tokens allowed in the bucket
- Refill rate: number of tokens insert into the bucket every x amount of time.
Some Call-Out points about Bucket
- If you wants to allow around 10000 req/sec then it will be good to have global bucket shared by all requests.
- If you want to throttle request based on IP address then each IP address should have there own bucket.
- It may possible that different API has different bucket. For example A User is allowed to post 50 tweets per min , 200 re-tweets per min or 20 follow req per min.
| Pros | Cons |
| Its simple and easy to implement | Difficult to manage bucket size and refill rate |
| Memory efficient | Race condition may cause an issue on distributed env. |
| Bulk req can be possible for short period of time, because a request can be serve as long as tokens are left in bucket |
Leaking Bucket Algorithm
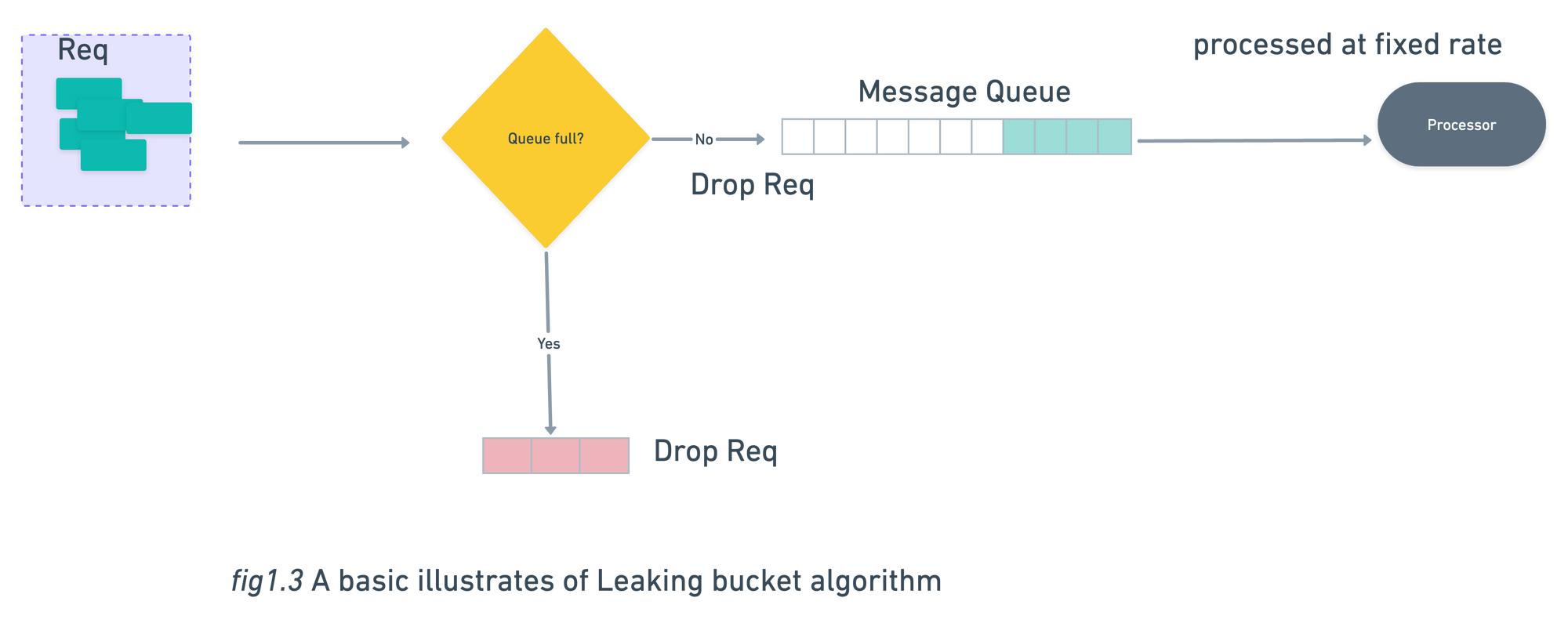
In Leaking Bucket Algorithm request are processed in fixed rate.
- When a new request arrives , the service check in queue if it is full request will be dropped else request will add in queue.
- Processor pull request from message queue at regular intervals.
Like Token Bucket Algorithm , Leaking Bucket Algorithm also has 2 parameters:
- Queue size: It holds the requests to be processed at a fixed rate.
- Outflow rate: It specify how many request can be processed at a fixed rate.
| Pros | Cons |
| Useful when stable outflow rate is needed | Huge traffic fills the queue with old request and if they are not processed in time , new requests will be rate limited |
| Memory efficient | Race condition may cause an issue on distributed env. |
Fixed Window Counter Algorithm
This algorithm work as follows:
- Create a fix size time windows, initialize a counter from zero and define a threshold value.
- On every request increase the counter by one.
- Request will be processed till counter ≤ threshold. When counter become greater than threshold all the new request will be dropped until a new window starts.
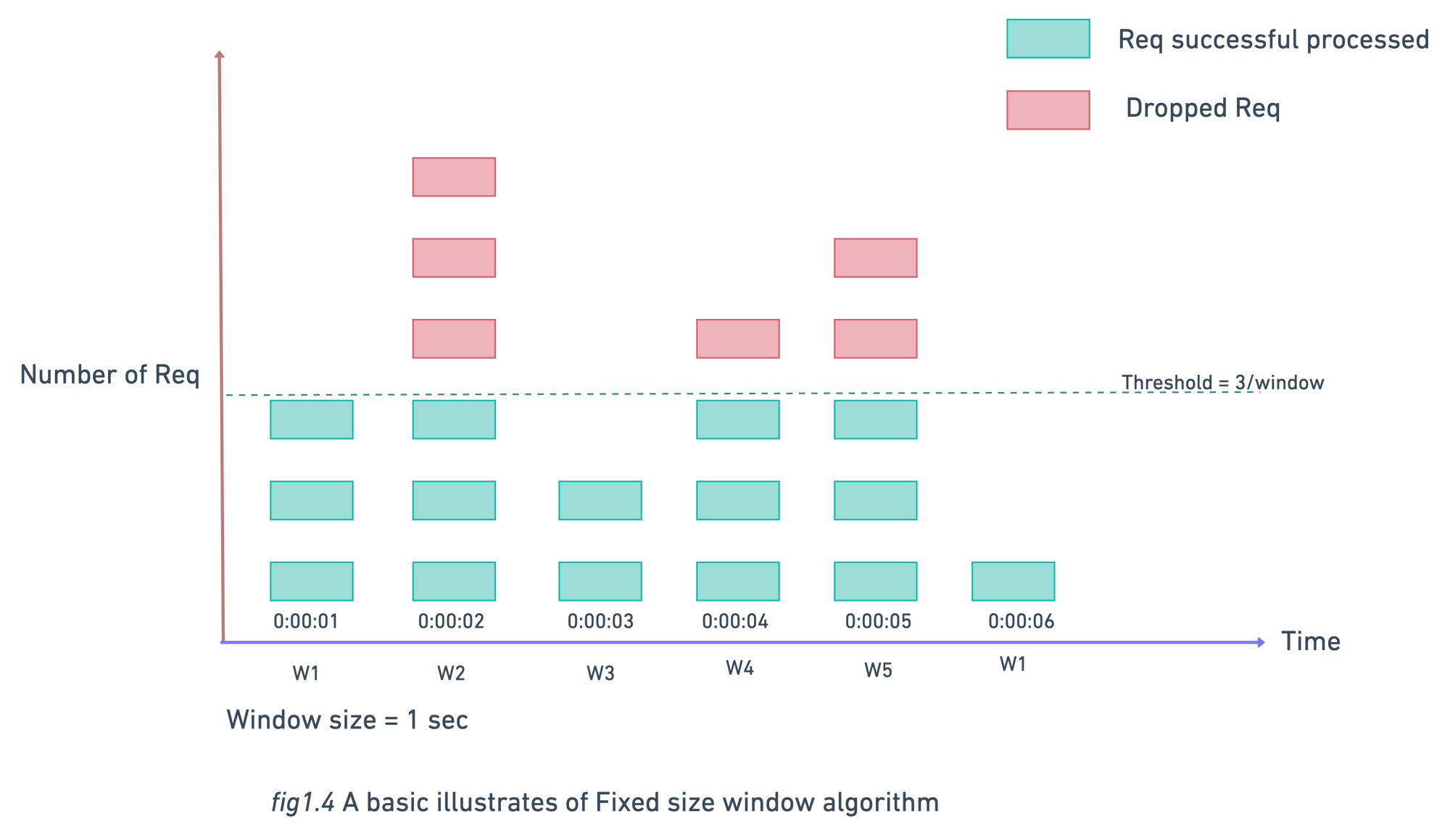
Major problem with this algo is when the system get a huge traffic at the edge of window , this algo is allowing the request more than the threshold .
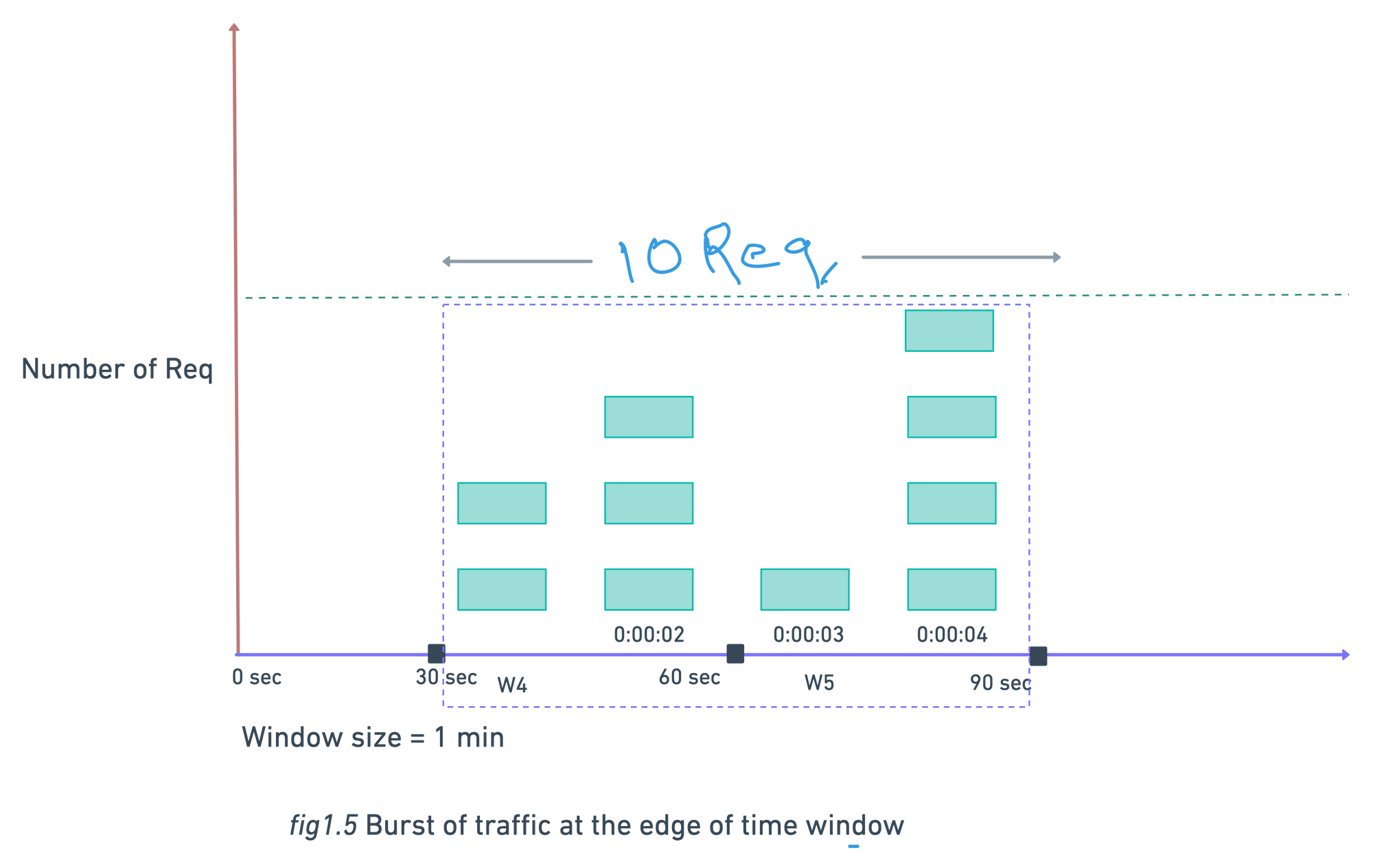
As seen in above fig.1.5 we have threshold of 5 requests/min but there are 5 requests between 30sec - 60sec and 5 other requests between 60sec - 90sec. So for 1-min window 10 requests processed between 30sec - 90sec which is twice of threshold.
| Pros | Cons |
| Resetting available quota at the end of a unit time window fits in some specific use cases. | burst traffic at the edges of a window could cause more requests than the allowed threshold |
| Memory efficient |
Sliding window log algorithm
It fixes the burst traffic issue of fixed size window algorithm. Lets see the working of algo:
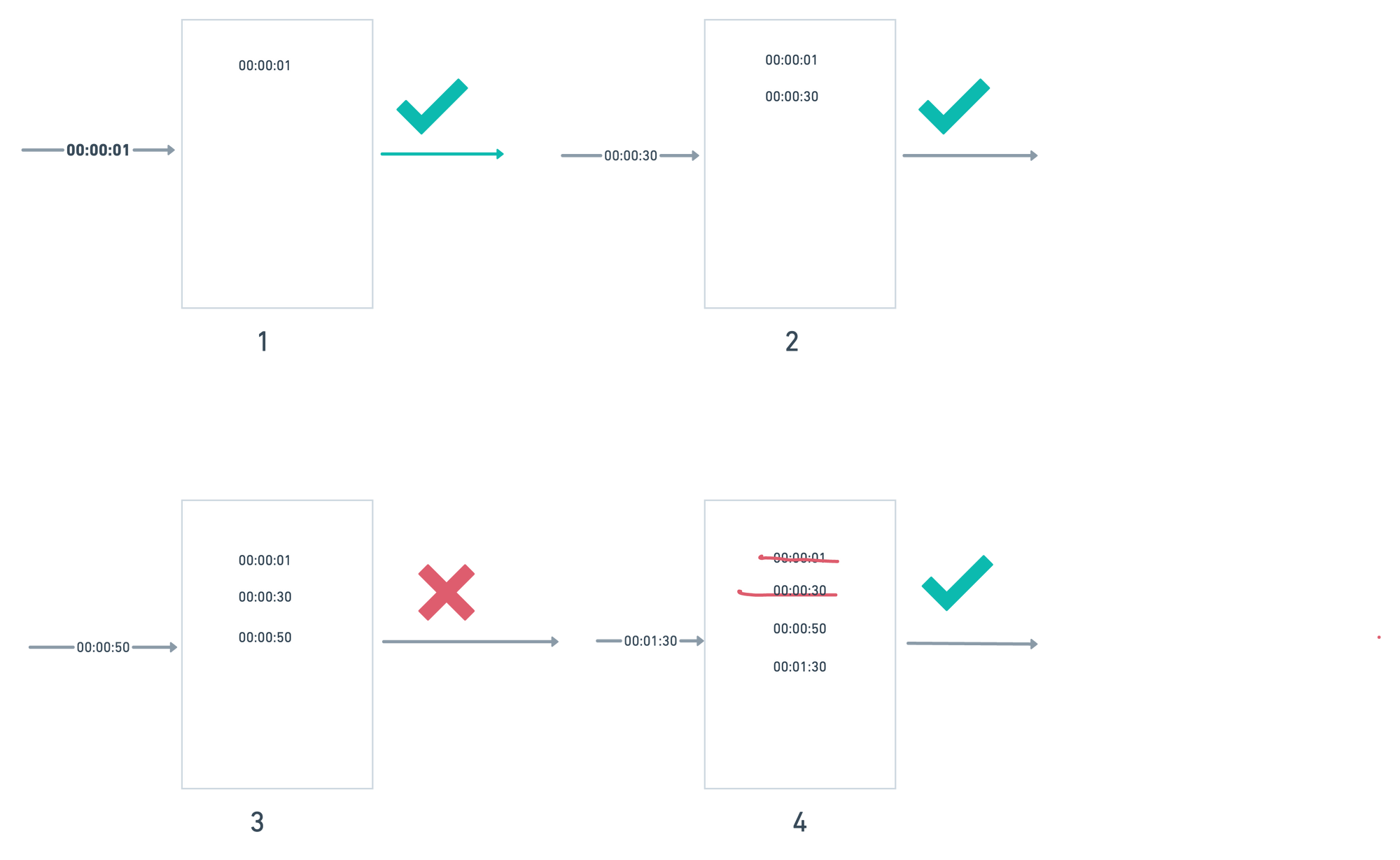
- Algorithm keep tracking request timestamps which usually stored in sorted sets of Redis.
- Keep removing all the outdated timestamps(older than the start of current time window) whenever a new request comes in.
- Add new request timestamp in the log.
- If count(log) <= allowed count then request will processed else dropped
| Pros | Cons |
| In any rolling window it is gurranted that requests will not exceed the rate limit. | Not memory efficient: Since we are managing a log ,which consume a lot memory |
Sliding window counter algorithm
This algorithm is the combination of fixed window and sliding window algo approach.
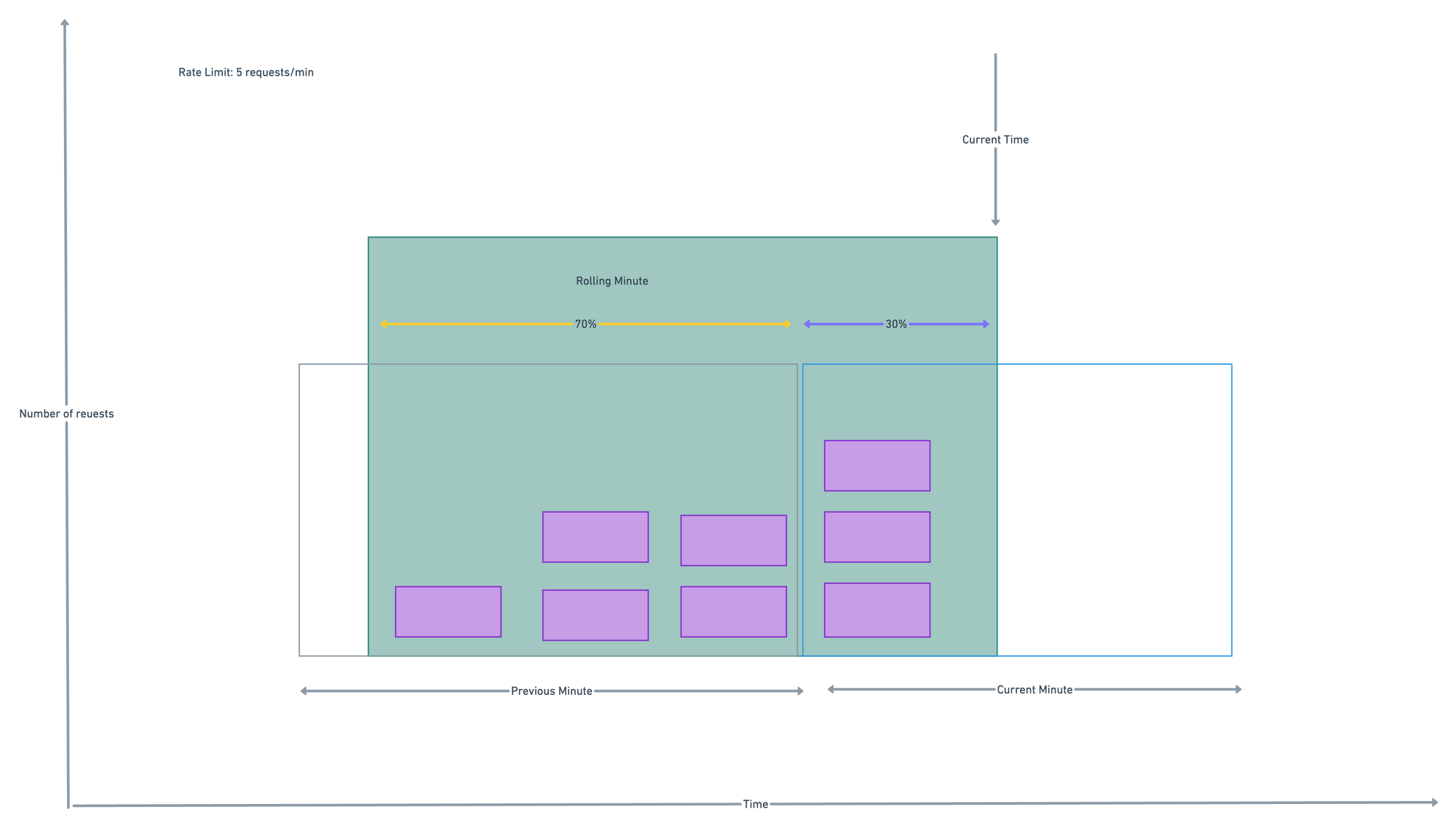
- let suppose quota of rate limiter is 7req/min and there are 5 requests in the previous minute and 3 in the current minute.
- For a new request that arrives at a 30% position in the current minute.the number of requests in the rolling window is calculated as :
- Using this formula, we get 3 + 5 * 0.7% = 6.5 request. Depending on the use case, the number can either be rounded up or down. In our example, it is rounded down to 6. Since the rate limiter allows a maximum of 7 requests per minute, the current request can go through. However, the limit will be reached after receiving one more request.
| Pros | Cons |
| It smooth the spikes of traffic because the rate is based on the average | It only works for not-so-strict look back window |
Lets Jump Into High Level Architecture
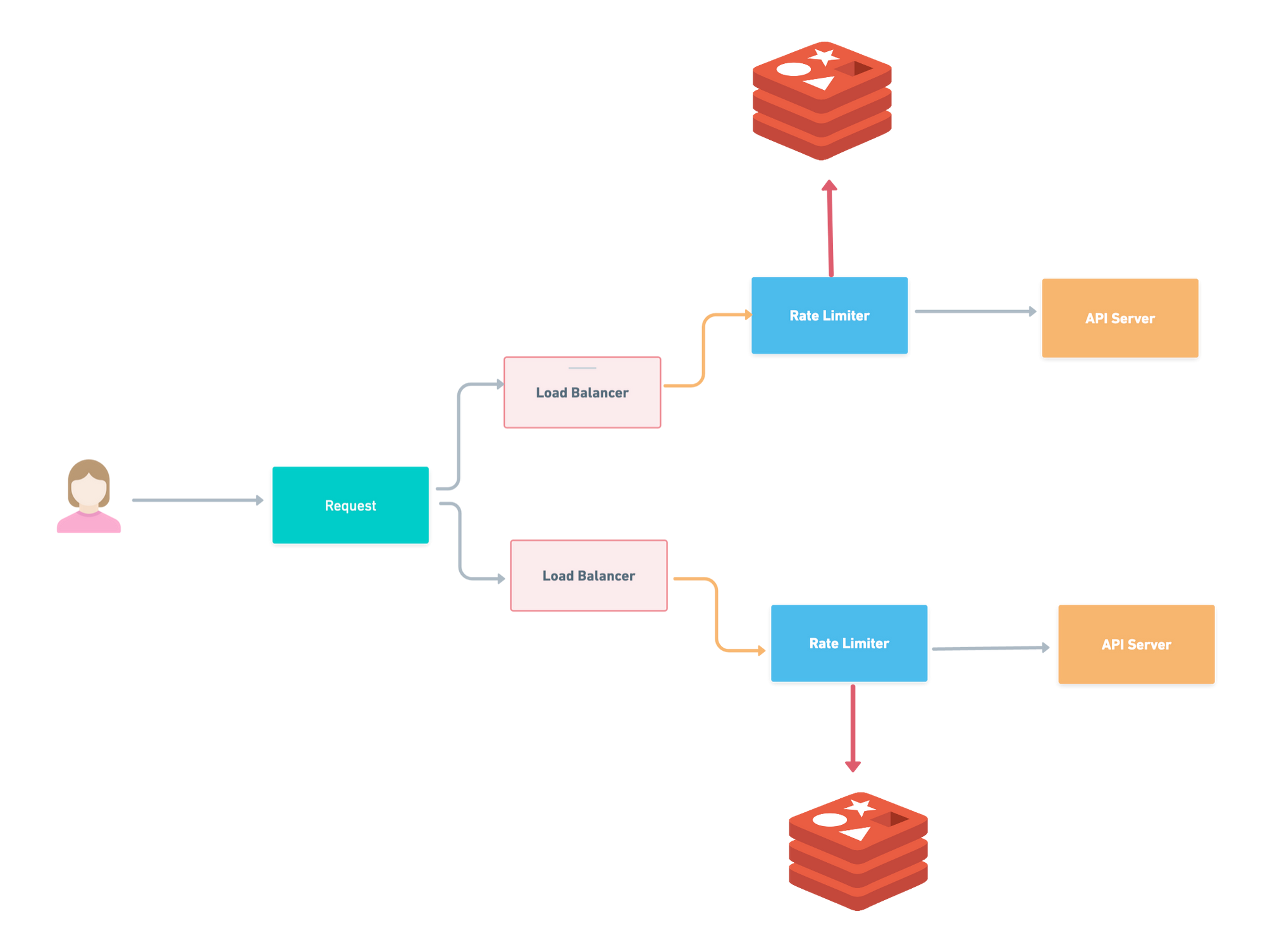
The basic explanation of all rate limiting algorithms is just create a counter and keep track of it whenever the request is coming. All the request will be disallowed if counter become greater than limit.
It is obvious we need counter value frequently so rather then putting it in any database ,keep it in some cache memory for example Redis. It is fast and supports time-based expiration strategy.
Deep Dive
Depending on the use cases we have to create different rules. Rules are generally stored on disk which is pulled by workers frequently and store them in cache.
Client Request first go through the middle-ware. Rate Limiter Middle-ware fetch the rules from cache. Based on counter and last logged request timestamp the rate limiter decide whether the request forwarded to the API Servers or return 429 too many requests error.
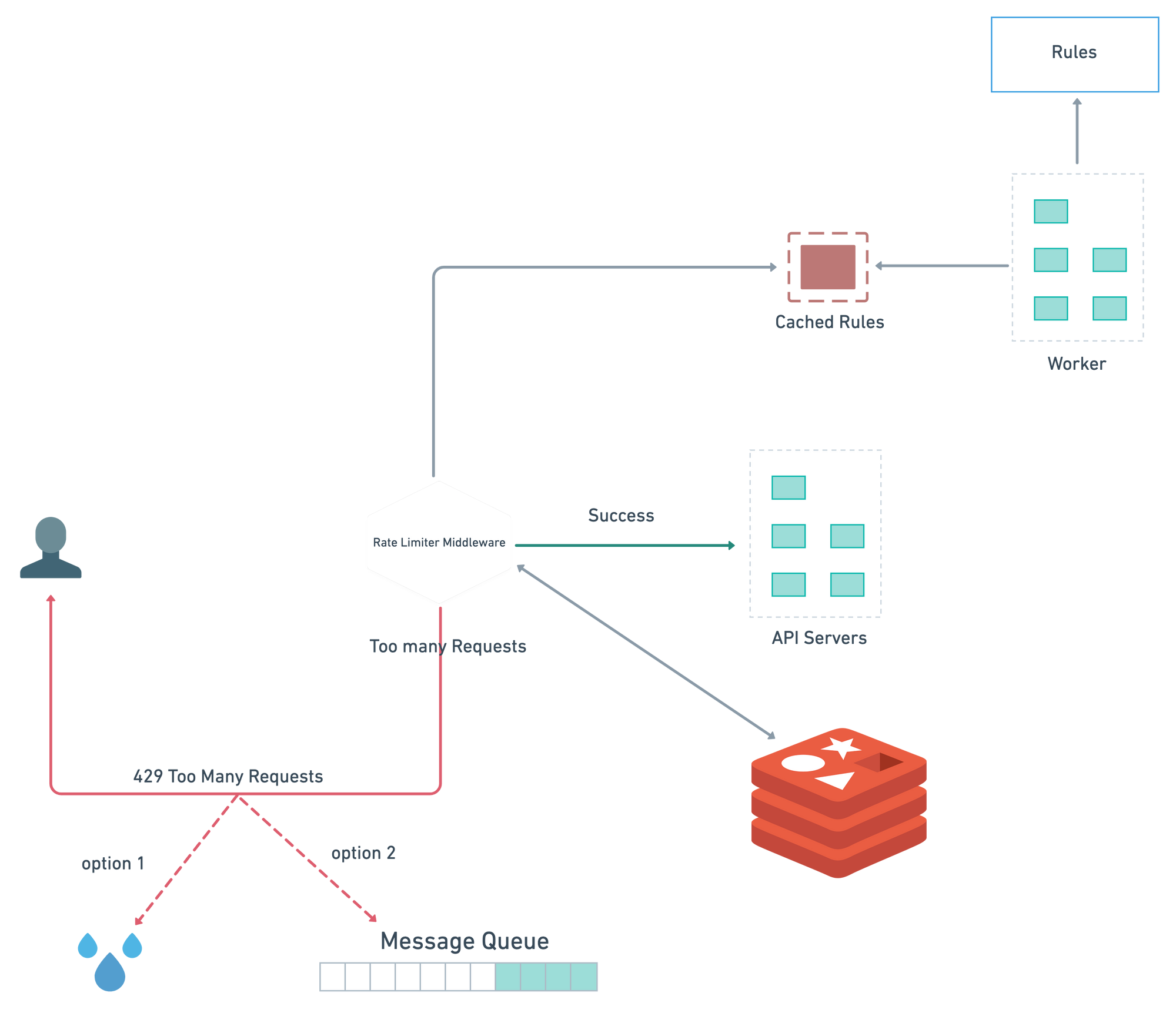
Challenges in Distributed Environment
Inconsistency
For a complex system multiple distributed servers have their own rate limiters and then we need to build a global rate limiter.
A client could surpass the global rate limiter individually if it receives a lot of requests in a small time frame.
Solution:
- Sticky Session: Load balancers will help here to sent a client request to exactly one node. The downsides include lack of fault tolerance & scaling problems when nodes get overloaded.
- Centralized Data Store: Use a centralized data store like Redis or Cassandra to handle counts for each window and consumer. Latency can be problem here but because of its flexibility this solution is good one.
Race Conditions
Each request gets the value of counter then tries to increment it. But by the time that write operation is completed, several other requests have read the value of the counter(which is not correct)
A simple solution is Locks but locks will significantly slow down the system. Again for solving this problem
we can use 2 strategies : Lua script and sorted sets data structure in Redis
Throttling
Throttling is the process of limiting the usage of the APIs by clients during a defined period. It can be defined at the application level and/or API level. When a throttle limit is crossed, the server returns HTTP status “429 — Too many requests”.
Types of Throttling:
- Hard Throttling: Requests cannot exceed the throttle limit.
- Soft Throttling: Limit can exceed to a certain percentage. For example, if we have rate-limit of 100 requests a minute and 10% exceed-limit, our rate limiter will allow up to 110 requests per minute.
- Elastic or Dynamic Throttling: the number of requests can go beyond the threshold if the system has some resources available. For example, if a user is allowed only 100 messages a minute, we can let the user send more than 100 messages a minute If any free resources available in the system.
References:
https://www.enjoyalgorithms.com/blog/design-api-rate-limiter
system-design-interview-an-insiders-guide L Alex
https://medium.com/geekculture/system-design-basics-rate-limiter-351c09a57d14